字串就是由零個或多個字元組成的序列。
下面程式碼介紹多種字串的函數
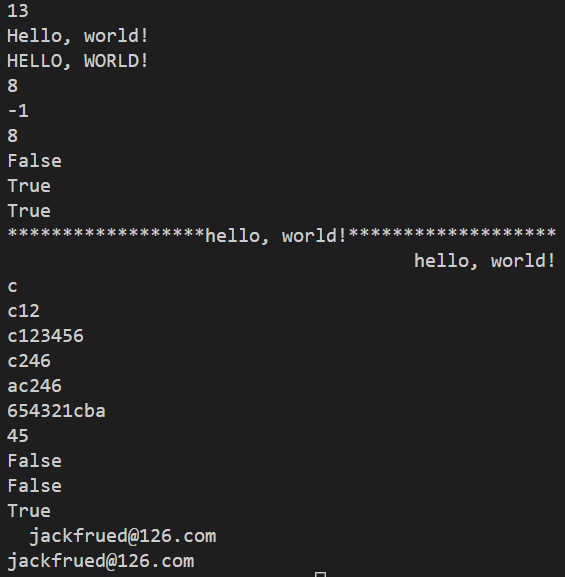
def main():
str1 = 'hello, world!'
print(len(str1)) # 計算字串的長度
print(str1.capitalize()) # 字串第一個字母變大寫
print(str1.upper()) # 將字串字母變大寫
print(str1.find('or')) # 從字串中找子字串所在位置
print(str1.find('shit'))
print(str1.index('or')) # 與 find 類似但找不到子字串時會異常
print(str1.startswith('He')) # 判斷字串是否以指定的字串為開頭
print(str1.startswith('hel'))
print(str1.endswith('!')) # 判斷字串是否以指定的字串為結尾
print(str1.center(50, '*')) # 將字串以指定的寬度置中並在兩側用指定的字元填滿
print(str1.rjust(50, ' ')) # 將字串以指定的寬度靠右放置左側用指定的字元填滿
str2 = 'abc123456'
print(str2[2]) # 從字串中取出指定位置的字元 (字串第一個元素為 str[0])
# 字串切片 字串[起始值:結束值:間隔值(預設為 1 )]
# 起始值如果不填就代表由最前方開始,結束值如果不填就代表算到最後
print(str2[2:5]) # 印出 str2[2] ~ str2[4] 的元素
print(str2[2:]) # 印出 str2[2] 後的所有元素
print(str2[2::2]) # 印出 str2[2] 後間隔 2 的所有元素
print(str2[::2]) # 印出從頭到尾間隔2的所有元素
print(str2[::-1]) # 印出以尾為首開始的所有元素
print(str2[-3:-1]) # 印出 str2[-3] ~ str2[-2] 的元素
print(str2.isdigit()) # 判斷字串是否由數字構成
print(str2.isalpha()) # 判斷字串是否由字母構成
print(str2.isalnum()) # 判斷字串是否由數字和字母構成
str3 = ' jackfrued@126.com '
print(str3)
print(str3.strip()) # 將字串左右兩側空格刪除
if __name__ == '__main__':
main()
除了字符串,還有其他數據結構,包括列表、元组、集合和字典。
下面程式碼介紹如何定義列表、使用列表元素及添加和刪除元素。
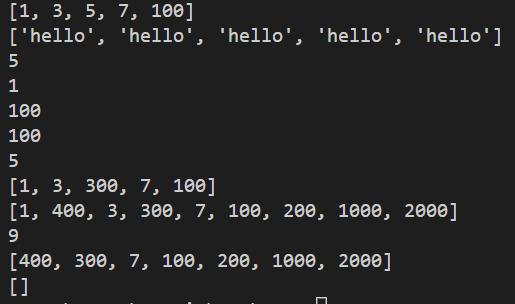
def main():
list1 = [1, 3, 5, 7, 100]
print(list1)
list2 = ['hello'] * 5 # 加入 5 個此元素置列表中
print(list2)
print(len(list1)) # 計算列表長度(元素個數)
print(list1[0]) # 印出列表的指定位置的元素
print(list1[4])
# print(list1[5]) # 超出列表範圍會發生異常
print(list1[-1])
print(list1[-3])
list1[2] = 300 # 將指定位置元素變為指定數據
print(list1)
list1.append(200) # 添加此數據元素到列表中
list1.insert(1, 400) # 添加此數據元素到指定位置
list1 += [1000, 2000] # 添加此數據元素到列表中
print(list1)
print(len(list1)) # 計算列表長度(元素個數)
list1.remove(3) # 刪除此數據元素
if 1234 in list1: # 判斷此數據元素是否在字串中
list1.remove(1234)
del list1[0] # 刪除指定位置的元素
print(list1)
list1.clear() # 清空列表元素
print(list1)
if __name__ == '__main__':
main()
列表也可以做切片,可以對列表的複製或將列表中的一部分取出来創建新的列表。
def main():
fruits = ['grape', 'apple', 'strawberry', 'waxberry']
fruits += ['pitaya', 'pear', 'mango'] # 添加此元素到列表中
for fruit in fruits: # 利用迴圈索引列表元素
print(fruit.title(), end =' ') # 印出索引的元素並將字首變為大寫
print()
fruits2 = fruits[1:4] # 添加指定元素(fruits[1] ~ fruits[3])至新列表中
print(fruits2)
fruits3 = fruits[:] # 可以透過完整切片来複製列表
print(fruits3)
fruits4 = fruits[-3:-1] # 添加指定元素(fruits[-3] ~ fruits[-2])至新列表中
print(fruits4)
fruits5 = fruits[::-1] # 添加以尾為首開始的所有元素至新列表中
print(fruits5)
if __name__ == '__main__':
main()

def main():
list1 = ['orange', 'apple', 'zoo', 'internationalization', 'blueberry']
# 利用 sorted 函數將列表排序,並且不會影響原列表
list2 = sorted(list1)
# 利用 reverse 關鍵字反轉列表
list3 = sorted(list1, reverse = True)
# 利用 key 關鍵字使列表根據字串長度進行排序
list4 = sorted(list1, key = len)
print(list1)
print(list2)
print(list3)
print(list4)
list1.sort(reverse = True) # 直接將原列表排序並反轉
print(list1)
if __name__ == '__main__':
main()

還可以使用列表的生成式語法創建列表。
import sys
def main():
f = [x for x in range (1, 10)] # 產生 1 ~ 9 的列表
print(f)
# 產生 x + y 的列表 (x 為 A ~ E,y 為 1 ~ 7))
f = [x + y for x in 'ABCDE' for y in '1234567']
print(f)
# 用這種語法創建列表需要耗費較多的内存空間
f = [x ** 2 for x in range (1, 10)] # 產生 1 ~ 9 中每個數平方值的列表
print(sys.getsizeof(f)) # 查看占用内存的字空間
print(f)
# 下面的程式碼創建的不是一個列表而是一個生成器
# 通过生成器可以獲取到數據但它不占用額外的空間存儲數據
# 每次需要數據時就通過内部的運算得到數據(需要花費額外的時間)
f = (x ** 2 for x in range (1, 10))
print(sys.getsizeof(f)) # 相比生成式生成器不占用空間
for val in f:
print(val, end = ' ')
if __name__ == '__main__':
main()

還有另外一種定義生成器的方式,利用 yield 關鍵字將一個普通函數改造成生成器函數。
下面程式碼是斐波拉切數列的生成器。
def fib (n):
a, b = 0, 1
for _ in range (n):
a, b = b, a + b
yield a
def main():
for val in fib (20):
print(val)
if __name__ == '__main__':
main()

元組與列表類似,不同之處在於元組的元素不能修改。
把多個元素組合到一起就形成了一個元組,所以它和列表一樣可以保存多條數據。
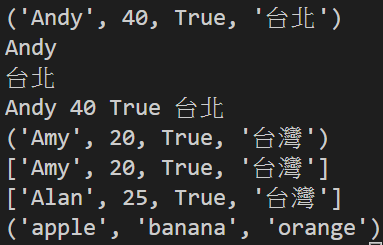
def main():
t = ('Andy',40 ,True ,'台北') # 定義元組
print (t)
print (t[0]) # 印出元組中的元素
print (t[3])
for member in t: # 索引元組中的值
print(member, end = ' ')
print()
t = ('Amy', 20 , True , '台灣') # 變數 t 引用了新的元組,原來的元組將被取代
print(t)
person = list(t) # 將元組轉換成列表
print(person)
person[0] ='Alan' # 列表是可以修改它的元素的
person[1] = 25
print(person)
#將列表轉換成元組
fruits_list = ['apple', 'banana', 'orange']
fruits_tuple = tuple(fruits_list)
print(fruits_tuple)
if __name__ == '__main__':
main()
Python 中的集合跟數學上的集合是一致的,不允許有重複元素,而且可以進行交集、並集、差集等運算
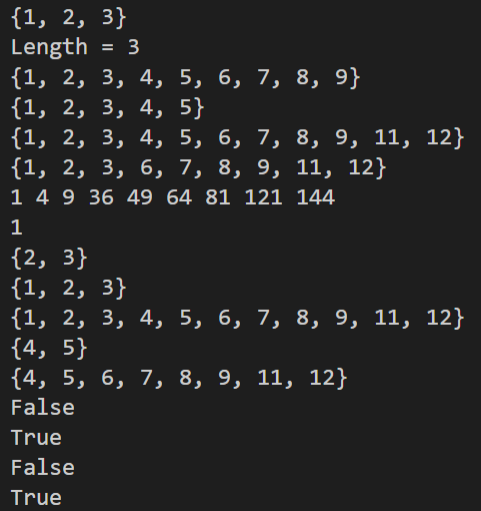
def main():
set1 = {1, 2, 3, 3, 3, 2} # 創建 set
print(set1)
print('Length =', len(set1)) # 印出 set 的長度
set2 = set(range (1, 10)) # 創建 1~9 的 set
print(set2)
set1.add(4) # 加入指定數據至 set 中
set1.add(5)
set2.update([11,12]) # 加入指定數據至 set 中
print(set1)
print(set2)
set2.discard(5) # 刪除中指定數據
if 4 in set2:
set2.remove(4) # 刪除中指定數據(remove 的元素如果不存在會引發 KeyError)
print(set2)
for elem in set2: # 索引集合中的數據
print(elem ** 2, end = ' ')
print()
#將元組轉換成集合
set3 = set((1, 2, 3, 3, 2, 1))
print(set3.pop()) # 刪除並取得 set 中的最後一項
print(set3)
# 集合的交集、聯集、差集、對稱差運算
print(set1 & set2) # print(set1.intersection(set2))
print(set1 | set2) # print(set1.union(set2))
print(set1 - set2) # print(set1.difference(set2))
print(set1 ^ set2) # print(set1.symmetric_difference(set2))
#判斷子集和超集
print(set2 <= set1) # print(set2.issubset(set1))
print(set3 <= set1) # print(set3.issubset(set1))
print(set1 >= set2) # print(set1.issuperset(set2))
print(set1 >= set3) # print(set1.issuperset(set3))
if __name__ == '__main__' :
main()
字典是另一種可變容器模,類似於我們生活中使用的字典,它可以存儲任意資料型態,與列表、集合。
不同的是,字典的每個元素都是由一個鍵和一個值組成的'鍵值對',鍵和值透過冒號分開。
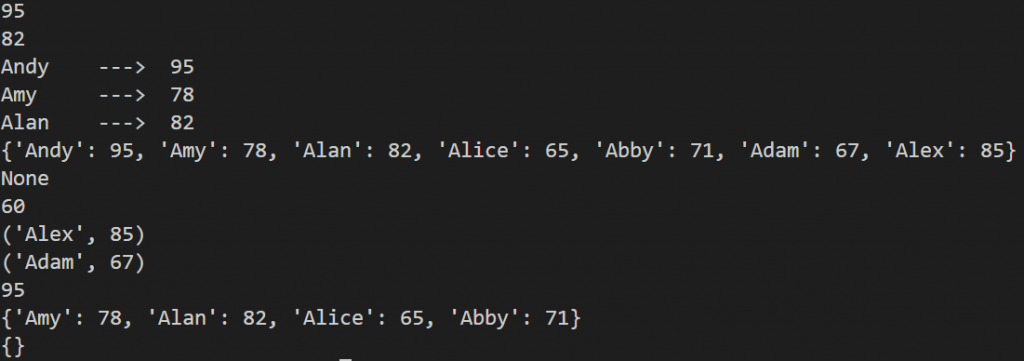
def main():
scores = {'Andy': 95, 'Amy': 78, 'Alan': 82}
print(scores['Andy']) # 利用鍵可以獲取字典中對應的值
print(scores['Alan'])
for elem in scores: # 對字典進行索引(索引的是鍵,再利用鍵取對應的值)
print ('%s \t---> %d ' % (elem, scores[elem]))
# 更新字典中的元素
scores['Alice'] = 65
scores['Abby'] = 71
scores.update(Adam = 67, Alex = 85)
print (scores)
if 'Albert' in scores:
print (scores['Albert'])
print (scores.get('Albert'))
# get方法也是利用鍵獲取對應的值,但是可以設置默認值
print (scores.get('Albert', 60))
# 刪除字典中的元素
print (scores.popitem()) # 刪除並取得最後一項
print (scores.popitem())
print (scores.pop('Andy', 100)) # 刪除並取得指定項的值
print (scores)
scores.clear() # 清空字典
print(scores)
if __name__ == '__main__':
main()
由於今天時間不太夠,所以我將這篇的練習移到明天做。
请问,列表排序,如果使用 sort,如何使用 key=len,根据元素的长短排序。
这是我修改后的代码, 将“list4 = sorted(list1, key=len)” 改成了 “list4 = list1.sort(key=len)”
def main():
list1 = ['orange', 'apple', 'zoo', 'internationalization', 'blueberry']
# 利用 sorted 函數將列表排序,並且不會影響原列表
list2 = sorted(list1)
# 利用 reverse 關鍵字反轉列表
list3 = sorted(list1, reverse = True)
# 利用 key 關鍵字使列表根據字串長度進行排序
list4 = list1.sort(key=len)
print(list1)
print(list2)
print(list3)
print(list4)
list1.sort(reverse=True) # 直接將原列表排序並反轉
print(list1)
但运行的结果,list4 为 None.

